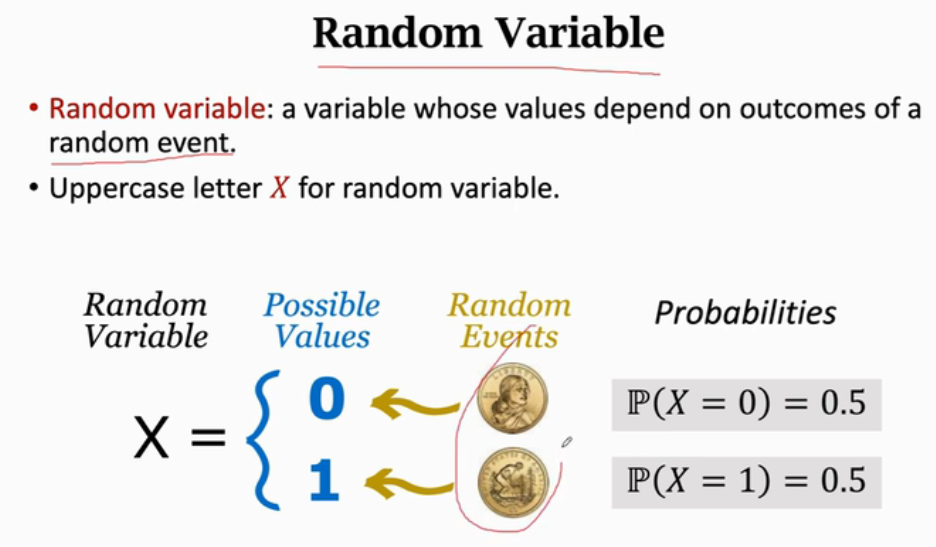
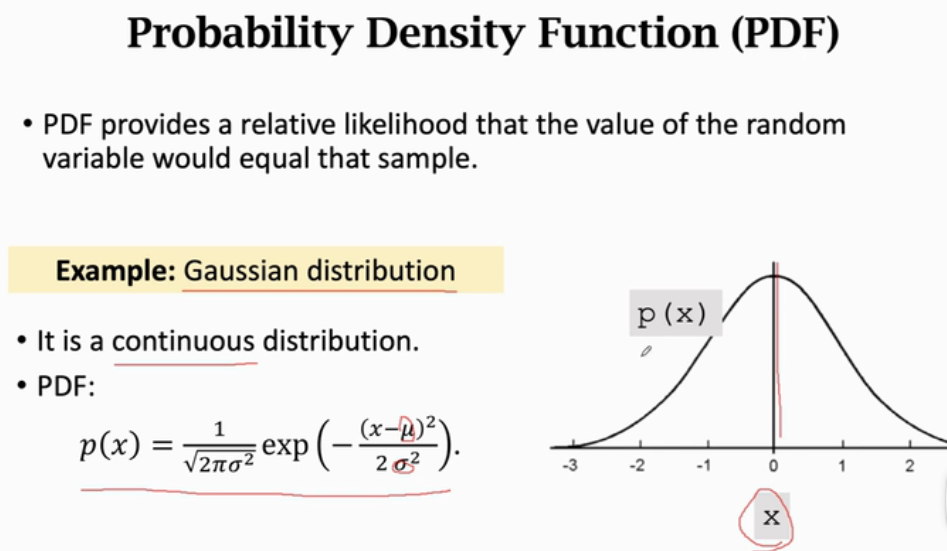
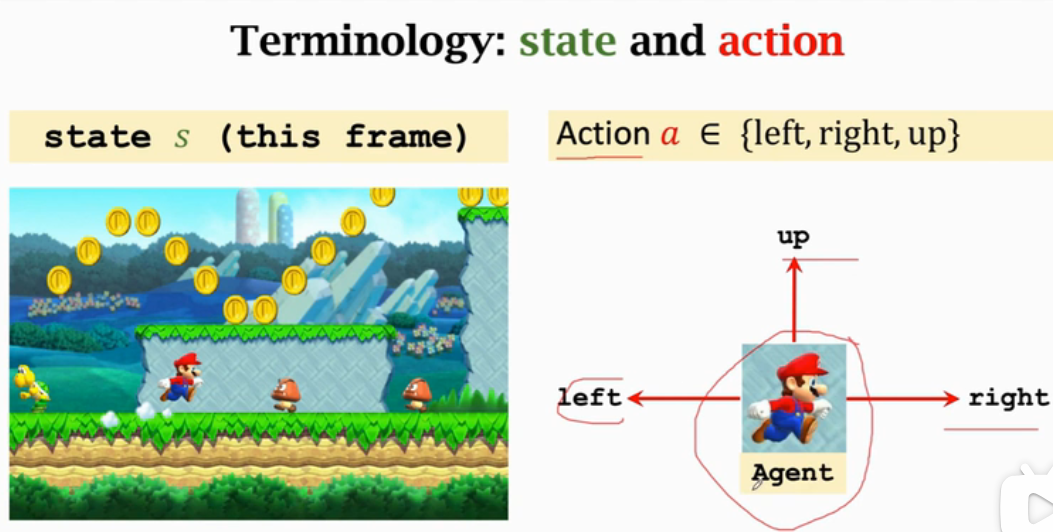
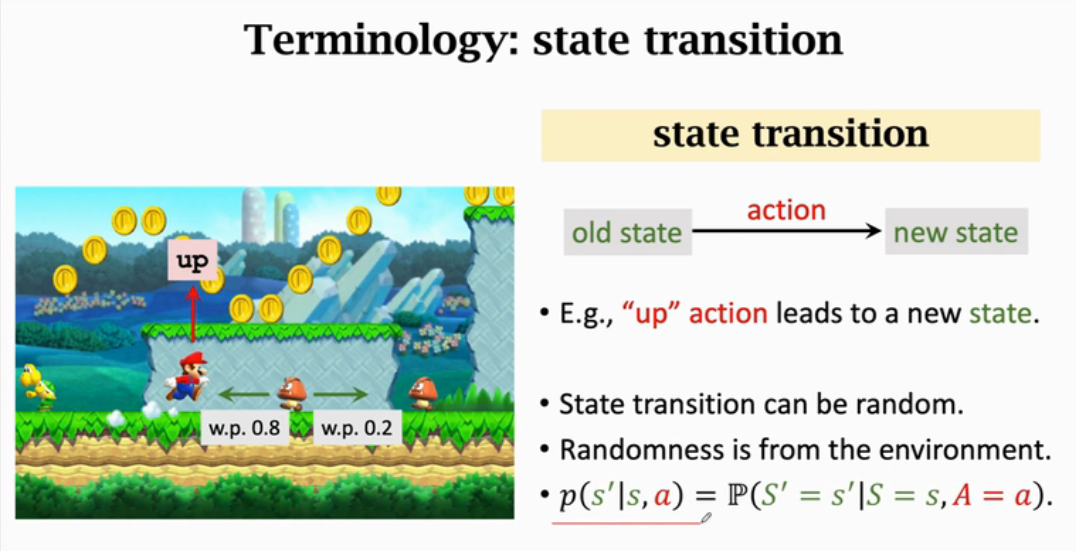
Appearance
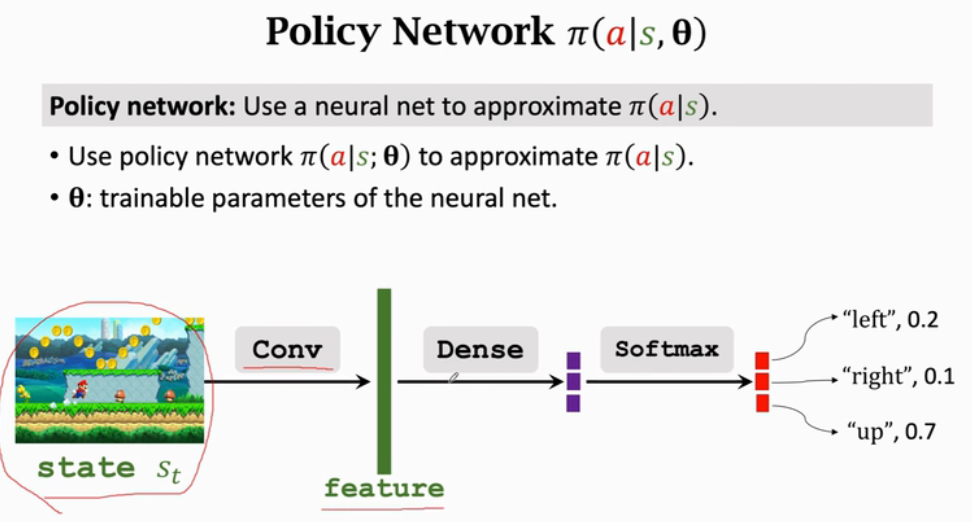
给定状态s做成动作a的概率
在s和a的条件下s'发生的概率
简单说就是用神经网络近似Q*(s,a)函数
怎么训练DQN?方式1:TD算法
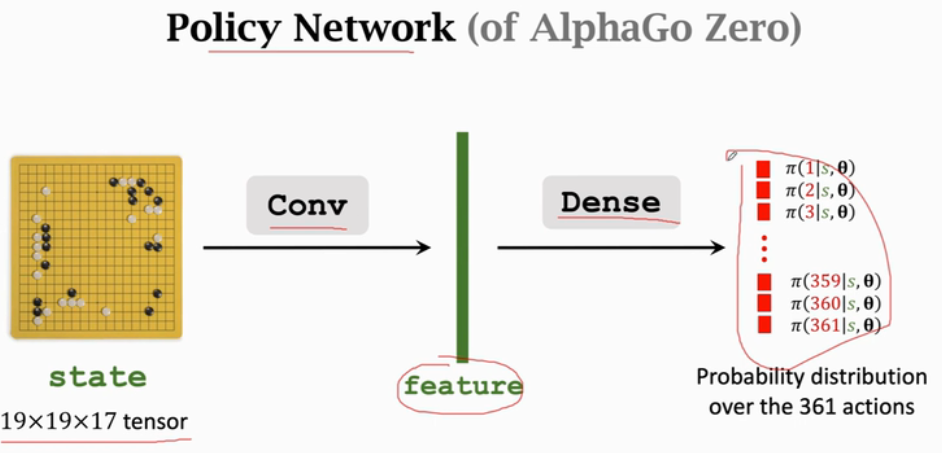
Policy Network
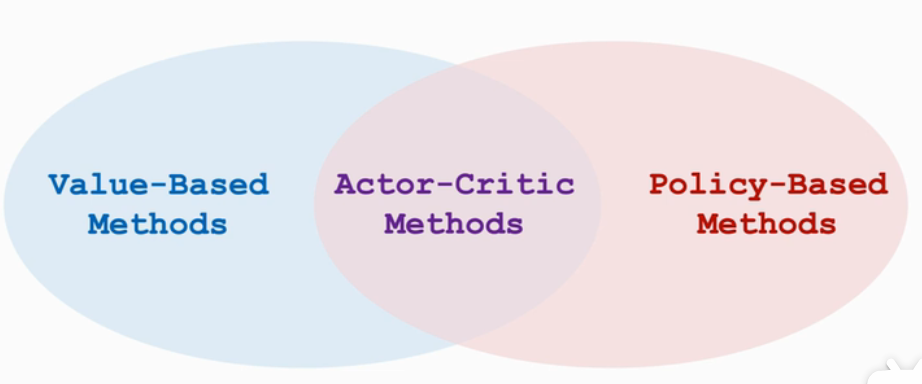
将价值学习和策略学习结合